Zeenea Scanner Setup
Architecture Overview
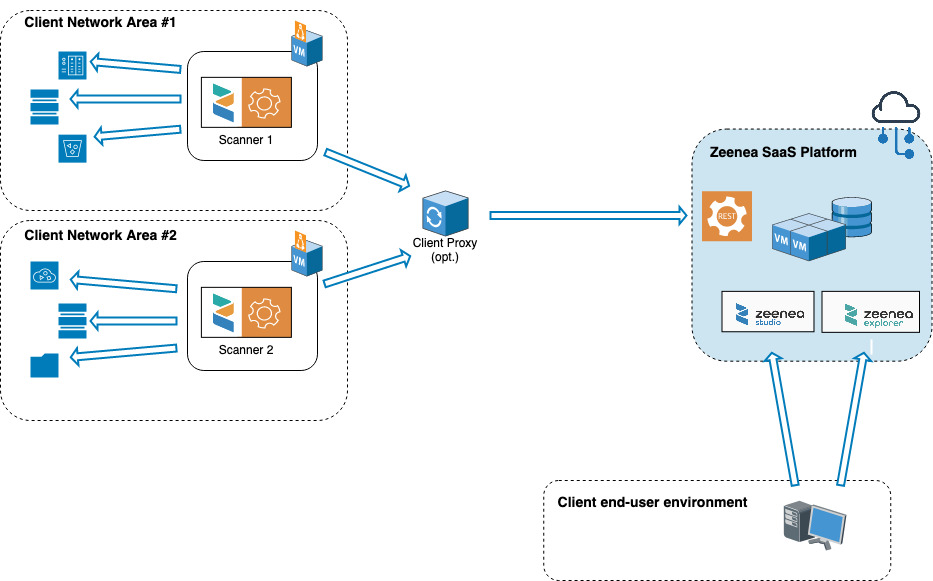
- Each instance of Zeenea Scanner must be deployed in your infrastructure.
- The Scanner's primary responsibility is to collect metadata from the systems you choose to connect to.
- The communication between the Scanner and your systems is initiated by the Scanner. It uses different protocols depending on the nature of the system with which the Scanner is communicating.
- The Scanner relies on connectors dedicated to communication with a particular type of system (e.g., Oracle, Table, Amazon S3 connectors, ...).
- The Scanner communicates with the Zeenea platform only on its own initiative: no incoming feed is required.
- The communication between the Scanner and the Zeenea platform is done via the HTTPS protocol (on default port: 443), in a secure way (TLS) and via an authentication based on an API key generated by you.
- This outgoing communication can optionally pass through a proxy.
The scanner process is expected to run continuously with special attention during the execution of its sub-processes (by default every night) and during the entire time users may use Zeenea platform.
Requirements for Installation
Hardware Requirements
Zeenea scanners must be installed on x86-64 Linux servers or Windows servers.
When running the scanner on a Linux, server, the following configurations are supported:
- Red Hat Enterprise Linux Server >= 6.8
- CentOS >= 7.3
- Ubuntu Server LTS >= 16.04
- Amazon Linux >= 2017.03
Standard sizing for a server:
- 4 cores
- 4 GB RAM minimum, 8+ GB recommended
- 20 GB of disk space
- The server can be virtually hosted.
Software Dependencies
The current Scanner version requires Java 11. OpenJDK or Oracle JDK can be installed indifferently.
Remember to validate your installation by checking it with the command # java --version.
You should see in reply the version number of Java and be able to verify that it is one of the supported versions.
Network Requirements
The Zeenea Scanner process will establish connections to the systems it is connected to and from which it will need to extract metadata.
Depending on the platforms, the protocols will vary and the flow openings will have to be carried out accordingly.
The Zeenea Scanner process will also exchange with the Zeenea SaaS platform. The network flow between the Zeenea Scanner process and the platform will therefore have to be allowed. The exchanges are always initiated by the Scanner process and are done in HTTPS. A proxy (with a possible authentication) can be configured.
Necessary Local Rights
The Zeenea Scanner service must be run with a dedicated user account (no login shell user account).
Under Linux, it is usually advisable to create a group with the same name.
This user must have read and/or write rights to the entire directory and subdirectories of the Scanner.
Installation
Our scanner is regularly updated to correct bugs and add improvements. We recommend updating it at least every 6 months.
Linux Environnement
Unless the binary is specifically provided to you by Zeenea, the Scanner can be downloaded as an archive by using a dedicated API entry point or via the Scanners monitoring page in Zeenea (Administration interface) where a download link is proposed.
If you decide to download the Scanner using the API, you have to create a dedicated API key. See Managing API Keys.
Then, use the previously created API key in the following command:
curl -L -H "X-API-SECRET: $APISECRET" "https://$hostname/studio/api-v1/agent/get-agent" -o scanner.tar.gz
With:
-
$APISECRET: the secret of the API key -
$hostname: your instance. For example: myenv.zeenea.appnoteThe API Key used for this request must be of type "Scanner".
Once the archive is downloaded, uncompress it in the folder of your choice, then proceed with the configuration.
Microsoft Windows: Install as a Service
Windows compatible versions of the scanner start with version 51.
Scanner 69 and Later
Installation of the Windows service uses Apache Procrun, part of the Apache Commons Daemon suite. From version 69 onwards, binaries for x86_64 architectures are supplied. You'll find them in the scanner's bin folder.
To install and update the Windows service, use the bin\zeenea-service.bat command, which will call the bin\prunsrv.exe command.
zeenea-service.bat offers the following options:
Option | Description | Default |
|---|---|---|
--JvmDll | Path to the Windows DLL to be used. If the argument is not specified, the DLL will be defined using the %JAVA_HOME% environment variable or the path to the "java" executable found in Path. | |
--ServiceName | Windows service name. | ZeeneaScanner |
--ServiceUser | Name of the Windows user running the service. | LocalSystem |
--LogLevel | Procrun log level. Values can be:
| Info |
--LogPath | Location of procrun log files. | "logs" subfolder in the scanner folder |
--JvmMx | Maximum size of the Java memory pool in MB. | 4096 |
Once the service has been set up, you can use bin\prunmgr.exe to monitor the service.
Run the following command with the service name used during registration to obtain a process monitoring icon in the system tray. Click on it to open the service settings window.
bin\prunmgr.exe //MS//
Scanner 68 and Previous
- Download windows binaries:
- Go to https://downloads.apache.org/commons/daemon/binaries/.
- In the
windowsfolder, download the archivecommons-daemon-1.3.4-bin-windows.zip.
- Unzip the archive.
- Copy the following files under the root folder of the Scanner:
prunmgr.exe- Depending on your architecture:
- If 32bits, copy
prunsrv.exethere. - If 64bits, copy
prunsrv.exefrom "/amd64" folder there.
- If 32bits, copy
- Using the MS DOS terminal, change your current directory to the root folder of the Scanner. Then execute the launch script by using this command
./bin/zeenea-service.batwith, as a parameter, the path to jvm.dll (should be under the following JRE's folder/bin/server/jvm.dll)- Command :
./bin/zeenea-service.bat "C:/path/to/dll/jvm.dll([--JvmMs 123] [--JvmMx 123] [--JvmSs 123]These are optional arguments to customize the amount of memory the JVM may allocate to different purposes. See JVM documentation for more information. - Once the command is executed, it should return without any error.
- You can verify the status of the service using this command:
./prunmgr.exe //MS//ZeeneaScanner. An icon should appear in your Windows task bar.
- Command :
prunmgr.exe : User Interface to manage and configure services once created.
prunsrv.exe : Command line application to manage (edit) services.
- You can rename
prunmgr.exetoZeeneaScanner.exeif you intend to run the application from Windows Explorer (instead of the Command Line). It will act as if it was this command:./prunmgr.exe //MS//ZeeneaScanner. - You can manage your service status using command available from procrun. See here for more information.
- Specific service log files are available in the
/service-logsfolder in your Scanner folder tree.
Configuration
Name the Scanner
The name will be the identifier of the Scanner. It will be used by Zeenea to distinctly identify the Scanner and allow the Connections associated with it to be identified.
- Only name the scanner using alphanumeric characters, underscores (_), and hyphens (-).
- Don’t use special characters, spaces characters, ...
- The name can be changed afterwards. However, in that event, Zeenea will keep track of a Scanner with the previous name with an offline status.
Select a name and avoid changing it.
Zeenea Scanner name is defined in a file named agent-identifier under the main directory of the scanner. Create such a file or just copy paste the previous one if you are upgrading the scanner to a new version and enter in this file the name that the Scanner will be given (on a single line).
Sample command to create this file:
echo "my-hadoop-cluster-scanner" > agent-identifier
The value my-hadoop-cluster-scanner in the example above is the name this Scanner will have.
Scanner Configuration
The configuration is done via the configuration file application.conf located in the conf/ directory
By default, the file is named application.conf.template. It must be renamed to (or duplicated with the name) application.conf.
Enter your Platform Address
You must enter the address of your Zeenea platform to allow the Scanner to retrieve the metadata. This is done by enhancing the zeenea-url property with the URL of your platform in the form:
https://[instance-name].zeenea.app
Example:
zeenea-url = "https://myenv.zeenea.app"
Enter Identifiers
The Scanner authenticates itself to the platform with an "Scanner" type API key containing a pair of information (id and secret). To generate an API key, refer to Managing API Keys.
The identifier and the secret must be entered in the node api-key, under id and key respectively.
Example:
authentication {
api-key {
secret = "eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJpc3MiOiJ6ZWVuZWEiLCJhdWQiOiJ6..."
}
}
Process Configuration (optional)
The frequency of execution of the various automatic processes carried out by the scanner is configurable under the "automation" node.
It is recommended to keep the default values except in very special cases.
Here are the processes triggered by the scanner:
- launch-inventory: Build a fresh new inventory of all items the connectors support from the source system. The inventory is what a Data Steward will see when opening the import wizard. By default, this process runs every 24H.
- update-schema: For all the synchronized items already imported into the data catalog (Datasets, Fields, Visualizations), update their source metadata from the source system. By default, this process runs every 24H.
- synchronize: Some connectors don't use an inventory to let the Data Steward import the items they want, but instead synchronize automatically all the items from the source system with Zeenea. This process will trigger these connectors. By default, this process runs every 24H.
- collect-fingerprint: Compute fingerprint and data profiling metrics for items having this option activated. By default, this process runs once a week.
- collect-data-sample: Collect a data sample from the last 30 entries of each Dataset, if the option is enabled in the Administration interface. By default, this process runs once a week.
Each process execution is configured with the help of a cron expression. Please, read carefully this article describing its syntax: https://www.quartz-scheduler.org/documentation/quartz-2.3.0/tutorials/crontrigger.html
Configure a Proxy (optional)
The gRPC protocol cannot be used in conjunction with a proxy.
It is possible to configure a proxy that will be used by the Scanner during exchanges with the Zeenea platform.
The configuration portion named proxy-configuration should be uncommented (# characters should be removed) while respecting the opening and closing braces.
Refer to your documentation to find out which proxy to use and how to configure it.
The parameters to be provided will be at least:
host: the proxy addressport: the proxy listening port
Other parameters may need to be filled in as well. In this case, uncomment them and value each one.
proxy-configuration {
host = "proxy-server"
# The port of the proxy server
port = 3128
# The protocol of the proxy server. Use "http" or "https". Defaults to "http" if not specified.
# protocol = "http"
# The principal (aka username) of the credentials for the proxy server
# principal = null
#
# The password for the credentials for the proxy server
# password = null
}
Modify Default Protocol (HTTP REST vs gRPC)
Why should you modify this?
The default REST based protocol is very convenient as it works almost everywhere. But, in some situations, the scanner may face one of its limits: the maximum size of the requests payload.
gRPC protocol is not concerned by this limitation. Thus it could make sense to consider gRPC in case of very important inventories being built.
Is my architecture ready for gRPC?
gRPC uses HTTP/2 as its transport protocol. Your infrastructure MUST support HTTP/2 from end to end. In case of any doubt, please read your proxies documentation to validate they do support HTTP/2 properly.
When configured to use gRPC, the scanner will communicate with a unique central entry point: grpc.zeenea.app. Make sure this address is accessible for the scanner.
How do I enable and configure gRPC?
In order to activate gRPC, you just have to add the following line to your scanner configuration file:
protocol = grpc
Once the scanner is restarted, it will start using gRPC to communicate with your Zeenea platform.
In case you need to specify a proxy, you can do this by editing your scanner configuration file this way:
grpc {
host = ""
port =
tenant = ""
}
Connections Configuration
You have to pay attention to the ability for the scanner to open a connection to the platforms it should communicate with: network routes should be enabled.
For more about our connectors, see Zeenea Connector Downloads.
New connections are defined using a dedicated configuration file under the connections folder of the Scanner.
Learn how to create, manage or delete a connection.
Using a Secret Manager
Starting from Scanner 73, you can rely on a Secret Manager to provide sensitive information to your connections, like your credentials.
Starting from Scanner 76, the Secret Manager can also be used for the Scanner configuration (except information defined inside the "secret-manager" node).
You can only define a single Secret Manager per Scanner.
Currently, the Scanner supports 2 different Secret Manager types:
- AWS Secret Manager
- A local file containing your secrets
AWS Secret Manager
Configuration example:
secret-manager {
key = "my-first-secret" # optional
provider = "aws-secrets-manager"
configuration = {
region = "eu-west-3"
# access_key_id = ""
# secret_access_key = ""
# profile = ""
}
# proxy {
# scheme = "http"
# hostname = "proxy"
# port = 8888
# username = "username"
# password = "pass"
# }
}
Depending on the scanner's host credentials, you may (or may not) need to provide some of the parameters defined in provider-configuration. The Scanner will try to use any existing Instance Role, Environment Variable, or AWS Configuration File being available.
The proxy object is optional.
File Secret Manager
Configuration example:
secret-manager {
key = "my-first-secret" # optional
provider = "file"
configuration = {
file-path = "/path/to/file"
}
}
Exclusively locally accessible files can be used here.
Such a file must adopt the following format:
my-first-secret {
key = "value"
some.complex.key = "again value"
token_databricks = "token secret"
s0m3-s3parat3d-k3y = "some value"
MY_URL = "http://localhost:8080""
filename = "zeenea-scanner-snapshot.json"
}
scanner_snowflake {
kh12345.eu-west-1.jdbc_url = "jdbc:snowflake://nnmfbau-kh90823.snowflakecomputing.com/""
kh12345.eu-west-1.username = SCANNER
kh12345.eu-west-1.password = value
kn98765.eu-west-1.jdbc_url = "jdbc:snowflake://nnmfbau-kn67972.snowflakecomputing.com/""
kn98765.eu-west-1.username = SCANNER
kn98765.eu-west-1.password = value
}
Secret Injection Syntax
Your connection file must contain a secret_manager object and can then use the following syntax to benefit from the Secret Manager:
${secret_manager.}
Here is an example (based on the local file sample above) for a connection:
name = "example-name"
code = "example-code"
connector_id = "databricks-unitycatalog"
secret_manager {
enabled = true
key = "my-first-secret"
}
connection {
url = "https://dbc-91ebdd08-4e3a.cloud.databricks.com""
token = ${secret_manager.token_databricks}
}
Starting from Scanner v76, the Scanner configuration (./conf/application.conf) can also use secrets managed by the Secret Manager (as well as regular ENV variables, not managed by the Secret Manager).
There is no need to define anything but the secret-manager, as explained above, and then use the same injection syntax.
For example, in the application.conf file, the API Key can be provided like this:
authentication {
api-key {
secret = ${secret_manager.api_key}
}
}
Hooks Configuration
You can configure hooks that will be called after a scanner job ends.
Learn how to configure a hook after a scanner job.
Dry Run
The scanner can be configured in dry-run mode.
The purpose of this mode is to test the inventory of the connections.
The scanner won't communicate with the platform and the inventory will be written to a file.
To enable it, you simply need to set the protocol to file and define a result file path.
protocol = file
file {
file-path = "/opt/zeenea-scanner-74/file-extract.json"
}
To execute the test, run the scanner with the inventory argument:
$ bin/zeenea-scanner inventory
Start the Scanner
Simple Start (test only)
The ./bin/zeenea-scanner script is used to start the Scanner.
This script must be started from the root directory of the Scanner.
This script can be executed with different options. For example, you can define the sizing of the JVM. All options are described in the help, via the -h option:
# ./bin/zeenea-scanner -h
It is important to allocate enough memory to the JVM. 8 GB are recommended.
In the following example, the command starts the Scanner process. The process will remain active even after logging out (nohup command) and the JVM will have a 8GB memory allocation.
# nohup ./bin/zeenea-scanner -J-Xmx8g &
Process Configuration in systemd
Scanning, especially in a production environment, is best defined as a process managed by systemd (or equivalent, depending on your OS).
We therefore strongly recommend this configuration.
Steps to Follow
- Copy and adapt the unit file (see example below).
- Reload the systemd configuration.
- Activate zeenea-scanner.
- Start the service
Example of Unit Files
This unit file must be adapted to your environment.
Name:
zeenea-scanner.service
Folder:
- If installing manually:
/etc/systemd/system - If installing via packaging system:
- RHEL, CentOS:
/usr/lib/systemd/system - Debian, Ubuntu:
/lib/systemd/system
- RHEL, CentOS:
- The user and group named in the file must have been created.
- The path to Zeenea must match or be adapted.
- The parameters passed to the Zeenea process must be adapted to your context.
Sample file:
[Unit]
Description=Zeenea Scanner
After=network-online.target
[Service]
Type=simple
ExecStart=/opt/zeenea/bin/zeenea-scanner -J-Xmx4g
WorkingDirectory=/opt/zeenea
User=zeenea
Group=zeenea
LimitNOFILE=524288
SuccessExitStatus=129 130 143
[Install]
WantedBy=multi-user.target
Useful Commands
- Activate the service:
sudo systemctl enable zeenea-scanner - Start the service:
sudo systemctl start zeenea-scanner - Reload systemd configuration:
sudo systemctl daemon-reload - Access systemd logs:
journalctl - Access to systemd logs limited to the service:
journalctl -u zeenea-scanner
If you experience issues while configuring your scanner, refer to Troubleshooting Scanners and Connections